Javascript的几种数据类型
最新的ECMAScript标准定义了7中数据类型:
如何判断一个Javascript数据类型
typeof 操作符
typeof是javascript原生提供的判断数据类型的运算符,它会返回一个表示参数的数据类型的字符串,但是需要注意的是,Null会返回object,数组属于Any other object也会返回object。
1 | const a = null; |
instanceof运算符
instanceof运算符可以用来判断某个构造函数的prototype属性所指向的对象是否存在于另外一个要检测对象的原型链上。
1 | const a = []; |
Object.prototype.toString
每一个继承自Object的对象都拥有toString的方法,如果一个对象的toString方法没有被重写过的话,那么toString方法将会返回”[object type]”,其中的type代表的是对象的类型。
1 | const a = ['Hello','Howard']; |
除了使用call(),还可以使用apply()
但是,Object原型链上的toString方法可以被重写,如果修改过toString方法,就无法准确判断数据类型
constructor
实例化的数组拥有一个constructor属性,这个属性指向生成这个数组的方法。
1 | const a = []; |
但是,constructor属性可以被改写,如果修改过constructor属性,就无法准确判断数据类型。
Array.isArray()
用来判断一个变量是否为数组,无论是修改Object.prototype.toString方法还是constructor属性都不会影响判断结果。
1 | const a = []; |
Vue实现数据绑定的原理
当把一个javascript对象传递给vue实例的data选项时,vue将遍历这个对象的所有属性,并使用object.defineProperty把这些属性转变为getter和settter。每个组件实例都有相应的watcher实例对象,它会在组件渲染过程中把属性记录为依赖,当依赖的setter被调用时,会通知watcher重新计算,watcher通过依赖找到使用getter获取该属性值的组件,并通知该组件重新渲染,渲染完成后再次把属性记录为依赖存入watcher实例。
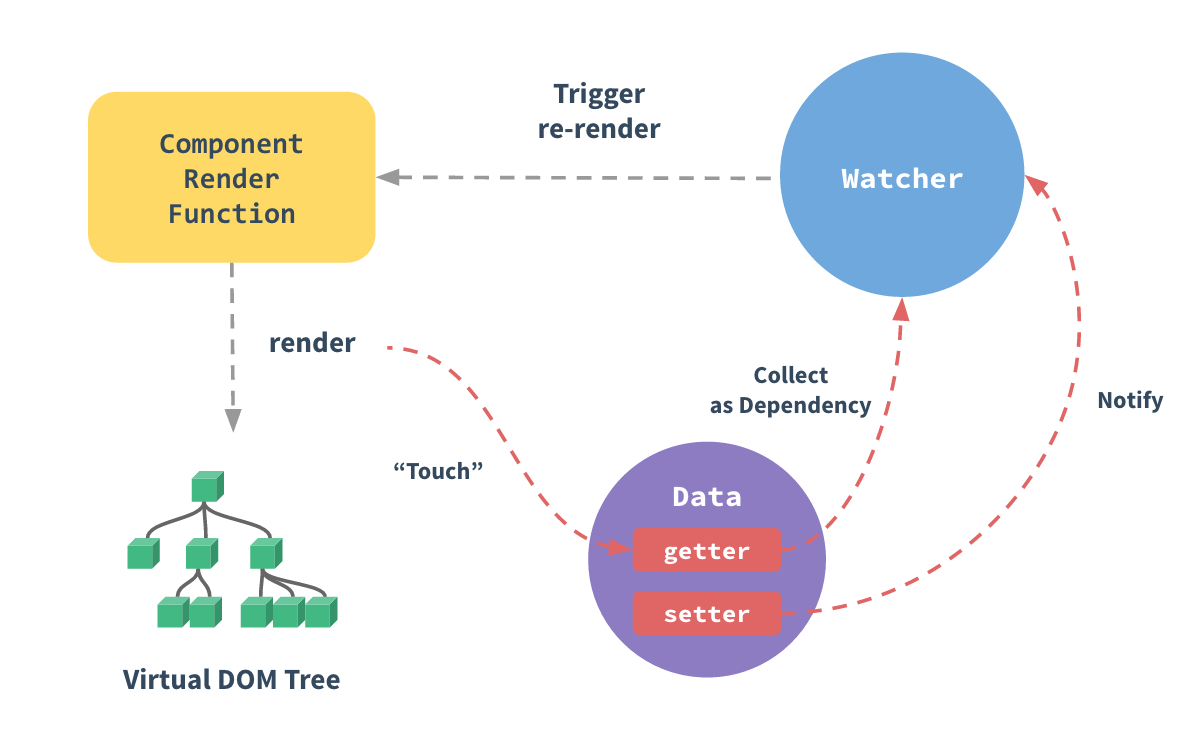
注意事项
- Vue不能检测到对象属性的添加或删除
- Vue不允许动态添加根基响应式属性
对于第一个问题可以采用Vue.set(object, key, value)方法来条线响应属性。对于第二个问题,只能在初始化实例前声明根级响应式属性,哪怕只是一个空值。
为什么vue 组件里 data 必须是一个function
因为每一次使用新的组件,都会有一个新的实例被创建,一个组件的data必须是一个函数,因此每个实例可以维护一份被返回对象的独立的拷贝
Proxy相比Object.defineProperty的优势是什么
Object.defineProperty的问题主要有三个
- 不能监听数组的变化
- 必须遍历对象的每个属性
- 必须深层遍历嵌套的对象
- 无法监听对象属性的增加和删除
Proxy的几个特点
- 针对对象
- 支持数组
- 支持13种拦截方式
- 作为新标准收到浏览器厂商的重点关注和性能优化
computed与methods
计算属性是基于他们的依赖进行缓存的,只有在相关依赖发生改变时才会重新求值。相比之下,每当触发重新渲染时,调用方法将总会再次执行函数。
http状态码
- 1xx消息
- 2xx成功
- 3xx重定向
- 4xx客户端错误
- 5xx服务器错误
cookie和session 的区别
- 存取方式的不同
- 隐私策略的不同
- 有效期上的不同
- 服务器压力的不同
- 浏览器支持的不同
- 跨域支持上的不同
Promise 链式调用
《ECMAScript 6 入门》一书中,阮一峰在Promise对象介绍Promise 是异步编程的一种解决方案,比传统的解决方案——回调函数和事件——更合理和更强大。
then方法接受两个参数,第一个是resolved状态的回调函数,第二个(可选)是rejected状态的回调函数。同时,then方法返回一个新的Promise实例,因此可以采用链式写法,在一个then后再掉调用一个then,而后一个then方法依旧可以接受两个参数的。
1 | getJSON("/post/1.json").then(function(post) { |
需要注意的是,一般使用Promise时总是配合catch方法使用,所以,此时不要在then方法里面定义Reject状态的回调函数,直接使用catch方法。好处是,catch方法总是可以捕获到在then方法执行过程中产生的Error,有利于后期排查。
1 | // bad |
一般总是建议,Promise 对象后面要跟catch方法,这样可以处理 Promise 内部发生的错误。catch方法返回的还是一个 Promise 对象,因此后面还可以接着调用then方法。而且,catch方法之后还可以继续执行then方法,甚至catch方法之后还可以执行catch方法。
在调用then方法实现链式调用时需要特别注意如何处理错误,没有catch住的错误会被Promise’吃掉‘
Vue中对Array的检测做了什么特殊处理
由于Object.defineProperty不能监听数组的变化,需要进行数组方法的重写,所以在Vue.js官方文档中数组更新检测中提到Vue提供一组观察数组的变异方法,使用这些方法才可以触发视图更新。
同时,文档中提到,由于Javascript的限制
- 利用索引直接设置一个项
- 直接修改数组长度
都不会触发视图更新,需要使用vm.$set和splice方法
简述同源策略
同源的三个要素
- 协议相同
- 端口相同
- 域名相同
当某个页面上执行的ajax请求的url与该页面的url中有上面三个中的任何一个不一样,就会产生跨域问题
解决跨域最常见的方案是后台服务端在Response-Header中设置Access-Control-Allow-Origin
F5 和Ctrl+F5的区别
在页面上使用F5和Ctrl+F5都可以实现刷新当前页面,不同点是F5会使用当前浏览器对该页面的缓存资源,Ctrl+F5会强制从服务器获取资源
请求中的size
打开控制面板查看Network中的资源请求,可以看到size一列中会出现4种情况
- 资源的大小
from disk cachefrom memory cachefrom ServiceWorker
from memory cache
表示该请求资源取自内存,不会再向服务器请求,关闭当前页面资源被释放
from disk cache
表示该请求资源取自磁盘,不会再向服务器请求,关闭当前页面资源不会被释放
资源的大小
当http状态码为200时,表示从服务器获取的资源大小
当http状态码为304时,表示与服务器通信报文的大小,不是资源的大小,此时资源从本地获取
from ServiceWorker
表示该资源取自ServiceWorker
造成size多重情况的原因
是因为使用F5和Ctrl+F5两种方式发送的请求头不一样(不同浏览器有些许差异)
F5 在chrome中
按F5后,请求状态码是200,资源的请求头中会有provisional headers are show字样,表示未与服务端正确通信,详细表头也不会显示,强缓存 from disk cache或者from memory cache都不会正确显示请求头
F5 在firefox中
按F5后,请求的状态码是304 Not Modified,这是因为firefox在F5发送请求时会在请求头添加If-Modified-Since字段,如果资源未过期,命中缓存,服务器会直接返回304状态码,浏览器会直接使用本地资源,这就是协商缓存
Ctrl+F5 在chrome和firefox中
请求头中多了Cache-Control:no-cache和Prafma:no-cache表示浏览器不接受本地缓存的资源,需要到源服务器进行资源请求,但是这个过程中其实可以使用缓存服务器中资源,不过需要到源服务器进行验证,验证通过才可以将缓存服务器的资源返回给浏览器
内存管理
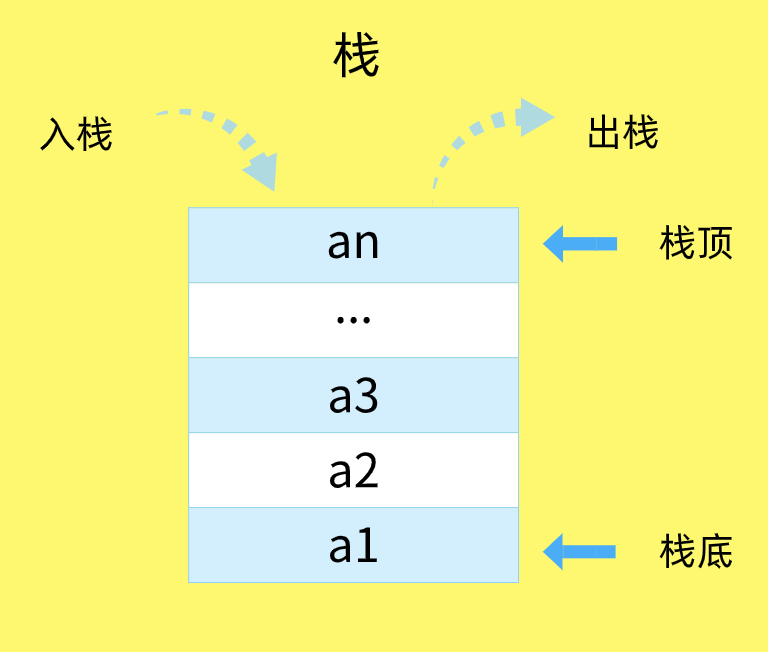
基础数据类型与栈内存
基本类型是保存在栈内存中的简单数据段,它们的值都有固定的大小,保存在栈空间,通过按值访问,并由系统自动分配和自动释放。 这样带来的好处就是,内存可以及时得到回收,相对于堆来说,更加容易管理内存空间。 JavaScript 中的 Boolean、Null、Undefined、Number、String、Symbol 都是基本类型。
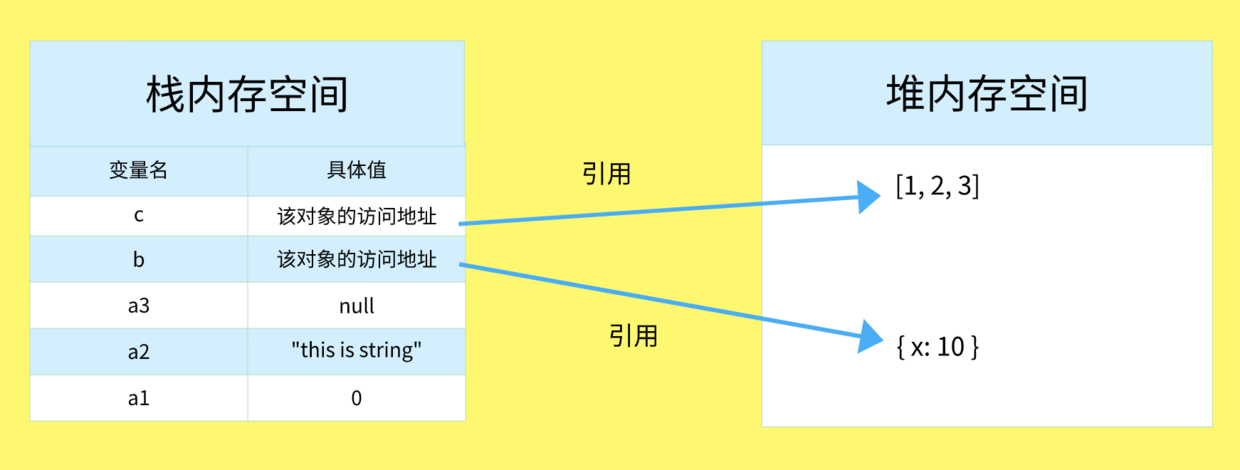
引用数据类型与堆内存
引用类型(如对象、数组、函数等)是保存在堆内存中的对象,值大小不固定,栈内存中存放的该对象的访问地址指向堆内存中的对象,JavaScript 不允许直接访问堆内存中的位置,因此操作对象时,实际操作对象的引用。 JavaScript 中的 Object、Array、Function、RegExp、Date 是引用类型。
浅拷贝和深拷贝
基本类型发生复制
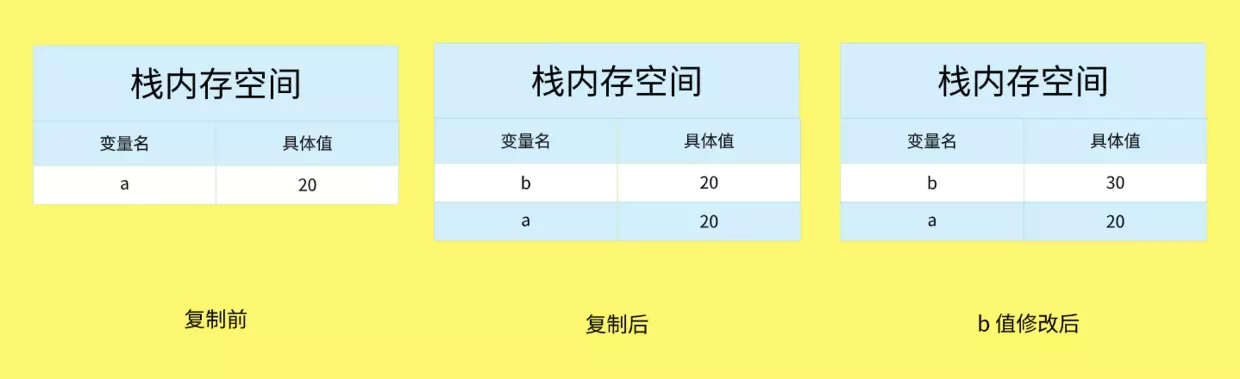
在栈内存中的数据发生复制行为时,系统会自动为新的变量分配一个新值,最后这些变量都是 相互独立,互不影响的。
引用类型发生复制
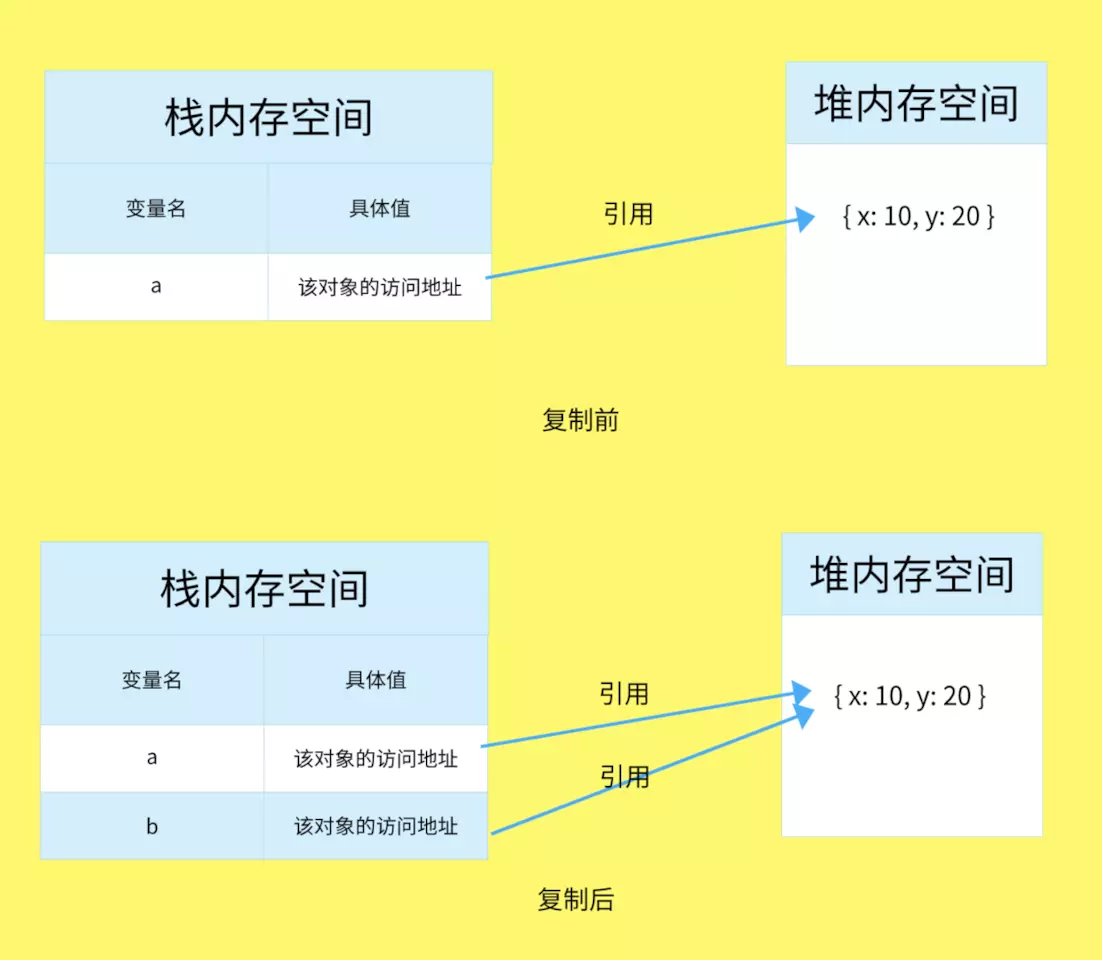
引用类型的复制,同样为新的变量 b 分配一个新的值,保存在栈内存中,不同的是,这个值仅仅是引用类型的一个地址指针。
他们两个指向同一个值,也就是地址指针相同,在堆内存中访问到的具体对象实际上是同一个。
因此改变 b.x 时,a.x 也发生了变化,这就是引用类型的特性。
浅拷贝
引用类型的复制就是浅拷贝,复制得到的访问地址都指向同一个内存空间,所以修改其中一个的值,另外一个也跟着改变。
深拷贝
复制得到的访问地址指向不同的内存空间,互不干扰,所以修改其中一个值,另外一个不会改变。
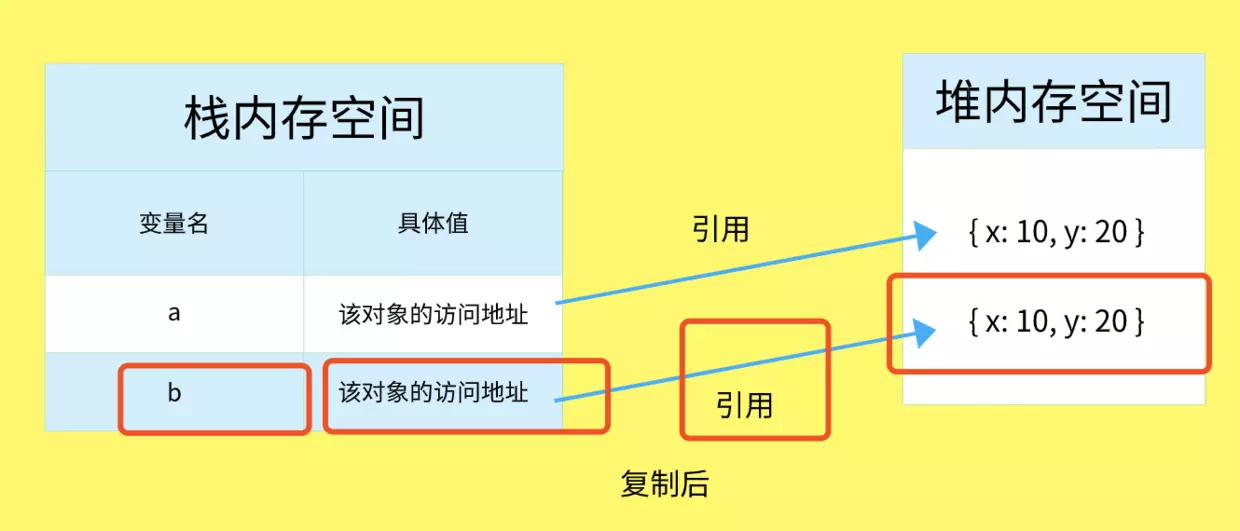
如何实现深拷贝
知晓引用类型的原理后实现深拷贝的方法就是创建一个新的堆内存控件,使复制出的栈内存空间指向新的堆内存引用。
数组
- for循环
- slice方法
- concat方法
- es6拓展运算
- JSON.parse和JSON.stringify
对象
- for in 循环
- JSON.parse和JSON.stringify(可实现多维对象的深拷贝)
- es6拓展运算
- Object.assign()(只能实现一维对象的深拷贝)
使用JSON.parse和JSON.stringify对对象进行深拷贝有一点需要注意:进行JSON.stringify() 序列化的过程中,undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成 null(出现在数组中时)。
参考:https://juejin.im/post/5d1b07716fb9a07efe2dd644
let和var 命令
基本用法
let 命令只在代码块能有效
不存在变量提升
var命令会发生“变量提升”现象,即变量可以在声明之前使用,值为undefined。为了纠正这种现象,let命令改变了语法应为,它所声明的变量一定要在声明后使用,否则报错。
1 | // var 的情况 |
上面代码中,变量foo用var命令声明,会发生变量提升,即脚本开始运行时,变量foo已经存在了,但是没有值,所以会输出undefined。变量bar用let命令声明,不会发生变量提升。这表示在声明它之前,变量bar是不存在的,这时如果用到它,就会抛出一个错误。
暂时性死区(temporal dead zone,简称TDZ)
只要块级作用域内存在let命令,它所声明的变量就“绑定”(binding)这个区域,不再受外部的影响。
1 | var tmp = 123; |
ES6 明确规定,如果区块中存在let和const命令,这个区块对这些命令声明的变量,从一开始就形成了封闭作用域。凡是在声明之前就使用这些变量,就会报错。
暂时性死区的本质就是,只要一进入当前作用域,所要使用的变量就已经存在了,但是不可获取,只有等到声明变量的那一行代码出现,才可以获取和使用该变量。
不允许重复声明
let不允许在相同作用域内,重复声明同一个变量。
1 | // 报错 |
变量提升
javascript引擎的工作方式是,先解析代码,获取所有被声明的变量,然后再一行一行地运行。这造成的结果,就是所有的变量的声明语句,都会被提升到代码的头部,这就叫做变量提升(hoisting)
1 | console.log(a); |
上面代码首先使用console.log方法,在控制台(console)显示变量a的值。这是变量a还没有声明和赋值,所以这是一种错误的做法,但是实际上不会报错。因为存在变量提升,真正运行的是下面的代码。
1 | var a; |
最后的结果是显示undefined,表明变量a已声明,但还未赋值。
参考:
垂直居中
使用绝对定位和负外边距
父元素使用相对定位,子元素采用绝对定位设置top:50%,margin为自身高度一半的负值
使用绝对定位和transform
父元素使用相对定位,子元素采用绝对定位设置top:50%,transform:translate(0,-50%)
使用绝对定位和margin:auto
父元素使用相对定位,子元素采用绝对定位,top和bottom设置为0,margin:auto,line-heigh设置为元素本身高度
使用父元素的padding
已知父子元素的高度,设置padding-top为父元素高度减去子元素高度的一半
使用flex布局
- 设置父元素
display:flex,align-items:center - 设置父元素
display:flex,flex-direction:column,justify-content:center
使用line-height对单行文本居中
设置line-height为元素高度即可
使用line-height和vertical-align对图片进行垂直居中
父元素设置line-height为自身高度,子元素设置vertical-align:middle
使用display:table和vertical-align:middele
父元素设置display:table,子元素设置diaplay:table-cell,vertical-align:middle
iframe和多窗口通信
每个iframe元素形成自己的窗口,既有自己的window对象,iframe窗口之中的脚本,可以获得父窗口和子窗口,但是,只有在同源的情况下,父窗口和子窗口才能通信,如果跨域,就无法拿到对方的DOM。
父窗口执行以下命令
1 | document |
子窗口执行以下命令
1 | window.parent.document.body |
对于完全不同源的网站,目前有两种方法,可以解决跨域窗口的通信问题。
- 片段识别符(fragment identifier)
- 跨文档通信API(Cross-document messaging)
片段识别符
片段标识符(fragment identifier)指的是,URL 的#号后面的部分,比如http://example.com/x.html#fragment的#fragment。如果只是改变片段标识符,页面不会重新刷新。
父窗口可以把信息,写入子窗口的片段标识符。
1 | var src = originURL + '#' + data; |
子窗口通过监听hashchange事件得到通知。
1 | window.onhashchange = checkMessage; |
同样的,子窗口也可以改变父窗口的片段标识符。
1 | parent.location.href = target + '#' + hash; |
window.postMessage()
HTML5 为了解决这个问题,引入了一个全新的API:跨文档通信 API(Cross-document messaging)。
这个 API 为window对象新增了一个window.postMessage方法,允许跨窗口通信,不论这两个窗口是否同源。举例来说,父窗口aaa.com向子窗口bbb.com发消息,调用postMessage方法就可以了。
1 | // 父窗口打开一个子窗口 |
postMessage方法的第一个参数是具体的信息内容,第二个参数是接收消息的窗口的源(origin),即“协议 + 域名 + 端口”。也可以设为*,表示不限制域名,向所有窗口发送。
子窗口向父窗口发送消息的写法类似。
1 | // 子窗口向父窗口发消息 |
父窗口和子窗口都可以通过message事件,监听对方的消息。
1 | // 父窗口和子窗口都可以用下面的代码, |
参考
深度作用选择器
如果你希望 scoped 样式中的一个选择器能够作用得“更深”,例如影响子组件,你可以使用 >>> 操作符:
1 | <style scoped> |
上述代码将会编译成:
1 | .a[data-v-f3f3eg9] .b { /* ... */ } |
有些像 Sass 之类的预处理器无法正确解析 >>>。这种情况下你可以使用 /deep/ 或 ::v-deep 操作符取而代之——两者都是 >>> 的别名,同样可以正常工作。
闭包
变量的作用域
变量的作用域分为全局变量和局部变量。javascript可以在函数内部直接读取全局变量。
1 | var n=999; |
另一方面,在函数外部无法读取函数内的局部变量。
1 | function f1(){ |
在函数内部声明局部变量时,不使用var 或者let const,则会被当做全局变量。
什么是闭包
闭包就是能够读取其他函数内部变量的函数。由于在Javascript语言中,只有函数内部的子函数才能读取局部变量,因此可以把闭包简单理解成”定义在一个函数内部的函数”。
所以,在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁。
1 | function f1(){ |
f2()被包含在f1()内,所以f1内部的所有局部变量,对f2都是可见的。但是反过来就不行,f2内部的局部变量,对f1就是不可见的。这就是Javascript语言特有的”链式作用域”结构(chain scope),子对象会一级一级地向上寻找所有父对象的变量。所以,父对象的所有变量,对子对象都是可见的,反之则不成立。既然f2可以读取f1中的局部变量,那么只要把f2作为返回值,我们就可以读取f1的内部变量了。
闭包的用途
它的最大用处有两个,一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。
1 | function f1(){ |
在这段代码中,result实际上就是闭包f2函数。它一共运行了两次,第一次的值是999,第二次的值是1000。这证明了,函数f1中的局部变量n一直保存在内存中,并没有在f1调用后被自动清除。
为什么会这样呢?原因就在于f1是f2的父函数,而f2被赋给了一个全局变量,这导致f2始终在内存中,而f2的存在依赖于f1,因此f1也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
这段代码中另一个值得注意的地方,就是”nAdd=function(){n+=1}”这一行,首先在nAdd前面没有使用var关键字,因此nAdd是一个全局变量,而不是局部变量。其次,nAdd的值是一个匿名函数(anonymous function),而这个匿名函数本身也是一个闭包,所以nAdd相当于是一个setter,可以在函数外部对函数内部的局部变量进行操作。
使用闭包的注意点
- 由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
- 闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
节流和防抖
什么是节流(throttle)
节流就是指在一段时间内对相同的事件只处理一次,避免短时内重复处理多次造成内存浪费引起程序卡顿。
有两种实现方式
时间戳
主要是记录上一次执行的时间戳,然后与当前时间戳进行比较,若超过指定的时间则执行一次;
1 | function throttle(fn, delay) { |
计数器
该方法主要利用计数器的标记进行节流,计时器在执行完一次操作之前标记不会被处理,因此在规定时间内的其它操作都不会被执行,从而达到了规定时间内只执行一次的目的。
1 | function throttle2(fn, delay) { |
什么是防抖
函数的目的是为了避免相同的事件触发的频率过快,即连续两次事件触发的执行时间之差不能低于某个限定值,相当于控制了事件执行的频率。
可以利用计时器延迟事件的执行来实现:
1 | function debounce(fn, delay) { |
由于每次触发都会执行clearTimeout,因此若前一次延迟操作没有被执行则会被自动取消,即前一次触发与后一次触发间隔时间小于规定间隔时间时前一次触发会被自动取消执行;
reactive 与 ref 的区别
- 有限的值类型:只能用于对象类型
- 不能替换整个对象
- 对解构操作不友好-失去响应性
Vue中的响应性是如何工作的
在 JavaScript 中有两种劫持 property 访问的方式: getter / setter 和 Proxy。Vue 2 使用 getter / setter 是出于支持旧版本浏览器的限制。而在 Vue 3 中则使用了 Proxy 来创建响应式对象。
但在 Vue3 中,reactive使用的内部实现是 Proxy,ref还是 getter / setter。
运行时 和 编译时响应性
- 运行时: 运行时响应性是指程序在运行时(即程序被执行时)动态地感知变化并作出响应
- 编译时响应性: 编译时响应性是指在程序编译阶段就确定数据依赖和变化的处理逻辑,而不是在运行时动态处理。这种机制通常借助静态分析来优化性能
模版 和 渲染函数
- 模版: 由于其确定的语法,更容易对模板做静态分析
- 渲染函数: 渲染函数一般只会在需要处理高度动态渲染逻辑的可重用组件中使用
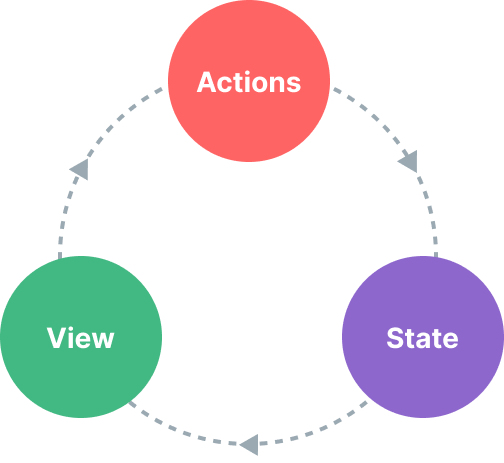
单向数据流
- 状态:驱动整个应用的数据源
- 视图:对状态的一种声明式映射
- 交互:状态根据用户在视图中的输入而作出相应变更的可能方式